paper:
code: caffe
ResNet
-
ResNet,一代经典,将深度网络结构设计以及各个视觉任务一下子向前推进了一大步,目前引用量已经到45k了。论文是CVPR2016的best paper,也是ILSVRC/COCO competitions 2015的全部五个视觉任务冠军,且精度相对第二名提升比例都非常高。
-
闲言少叙,言归正传,这里主要是发现再次对ResNet的不同网络结构做一次回顾(Plain net、Residual net(ResNet18/34)、Bottleneck residual module(ResNet50/101/152))
Details
- deep residual learning
- residual learning的阐述直接参考slide中的这一页了,如下
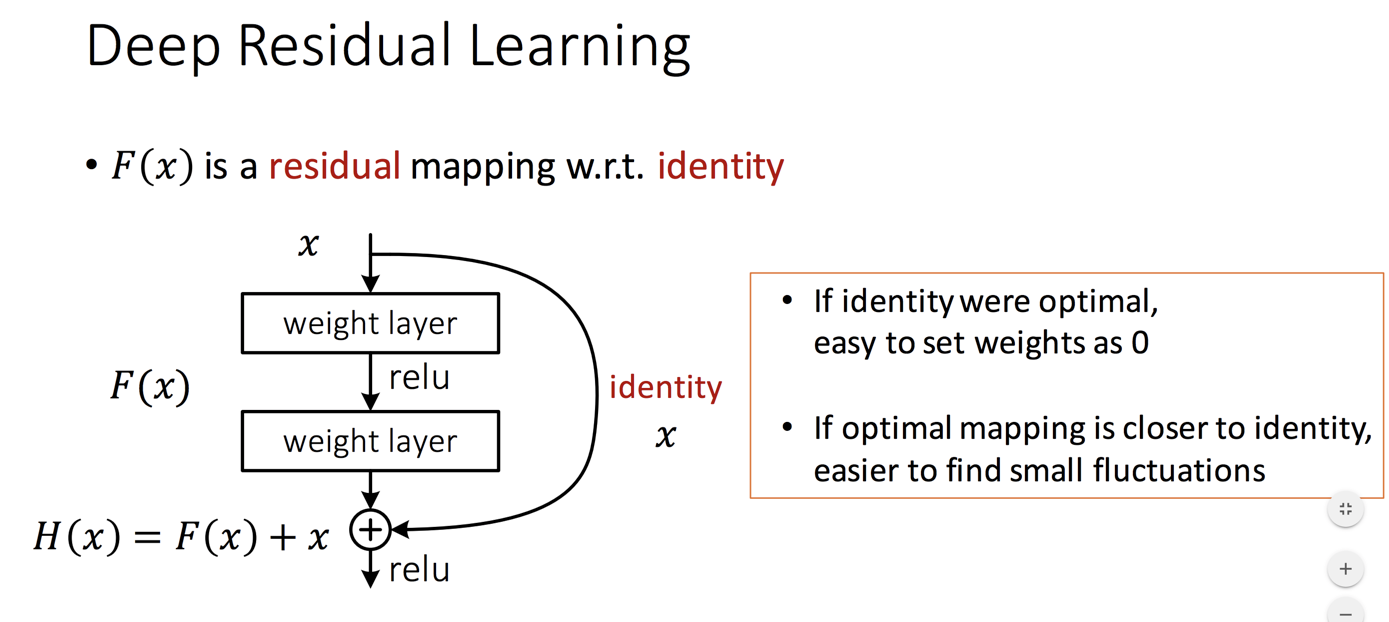
- residual learning的阐述直接参考slide中的这一页了,如下
- 浅层resnet网络结构
- 浅层的resnet由vgg19演变过来
- vgg19:输入图像大小为\(224 \times 224 \),经过5次降采样,最后的特征图大小为\(7\times 7 \times512 \),然后接上3个fc层,进行分类。vgg全部的conv大小都是\(3 \times 3\)
- plain net: 34层,将vgg最开始的\(3 \times 3\) conv改为\(7 \times 7\)的stride conv,然后接上4个module(每个module分别包含不同个数的conv),每接一个module,特征图大小降采样一倍,同时kernel个数也增加一倍,而每个module中的kernel大小、个数都是一致;最后,同样经过5次降采样,得到\(7 \times 7 \times 512\)。然后,用avg pooling代替两个fc(pooling的kernel size等于7),再将结果送入最后的fc进行分类
- residual net: 34层,在plain net的基础上,每2个conv后加入一个residual连接,连接的方式为conv(+bn)+relu+conv(+bn)+elewise sum + relu,如下图
- 这里作者对比了多种shorcut mapping的方式,发现如果用identity效果是最好的
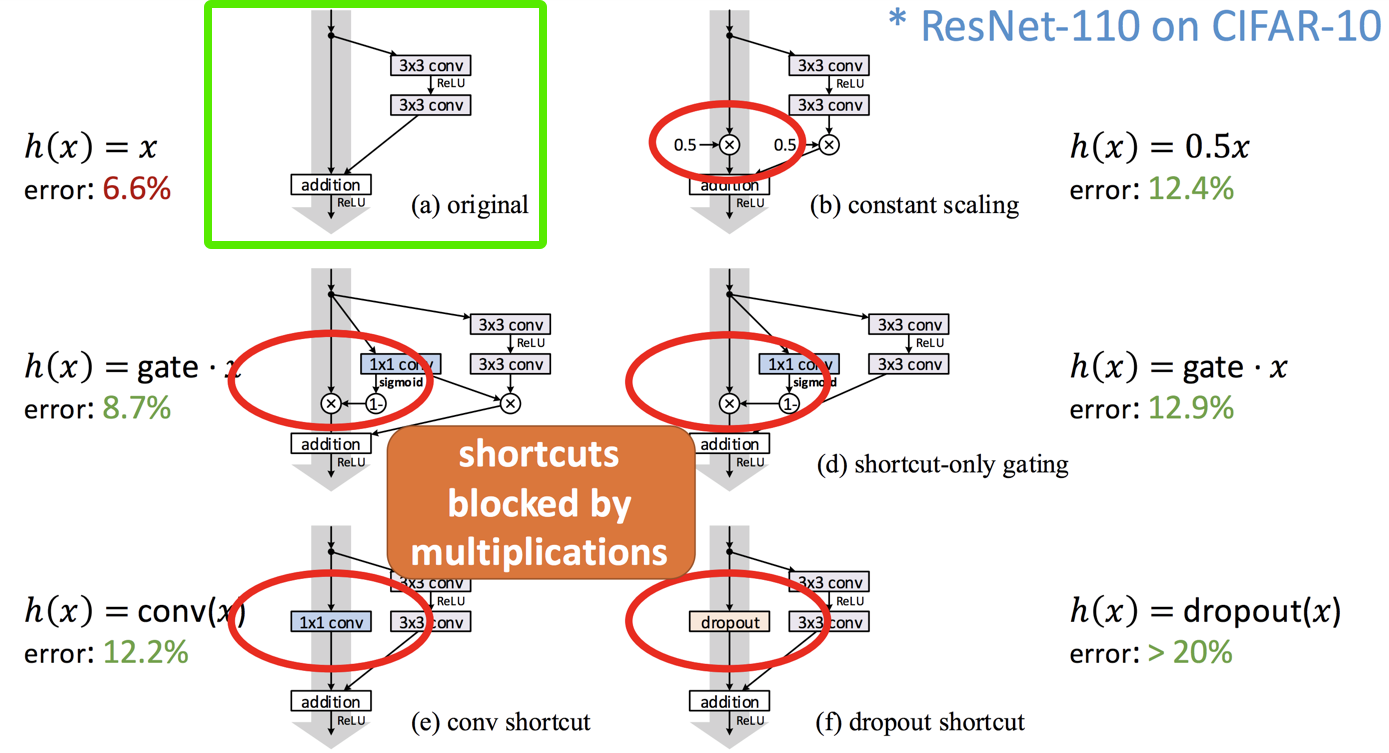
- 再者,作者文中由对比用于改变kernel个数的projection shortcut和identity的shortcut的效果,虽然,projection shortcut能够一定程度上减少错误率,但并不明显,且其也不是解决梯度退化问题的关键,因此作者只在每个module连接处使用projection shortcut,用于匹配大小和kernel个数
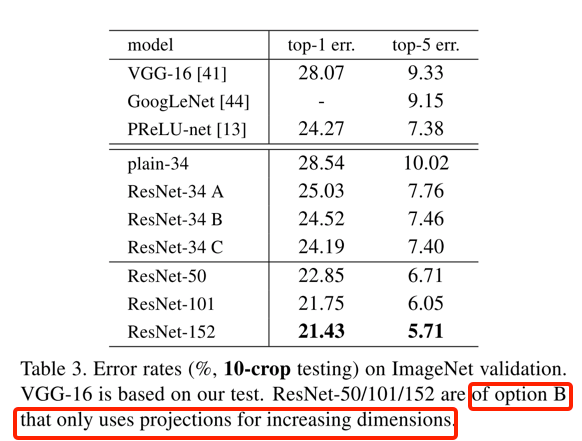
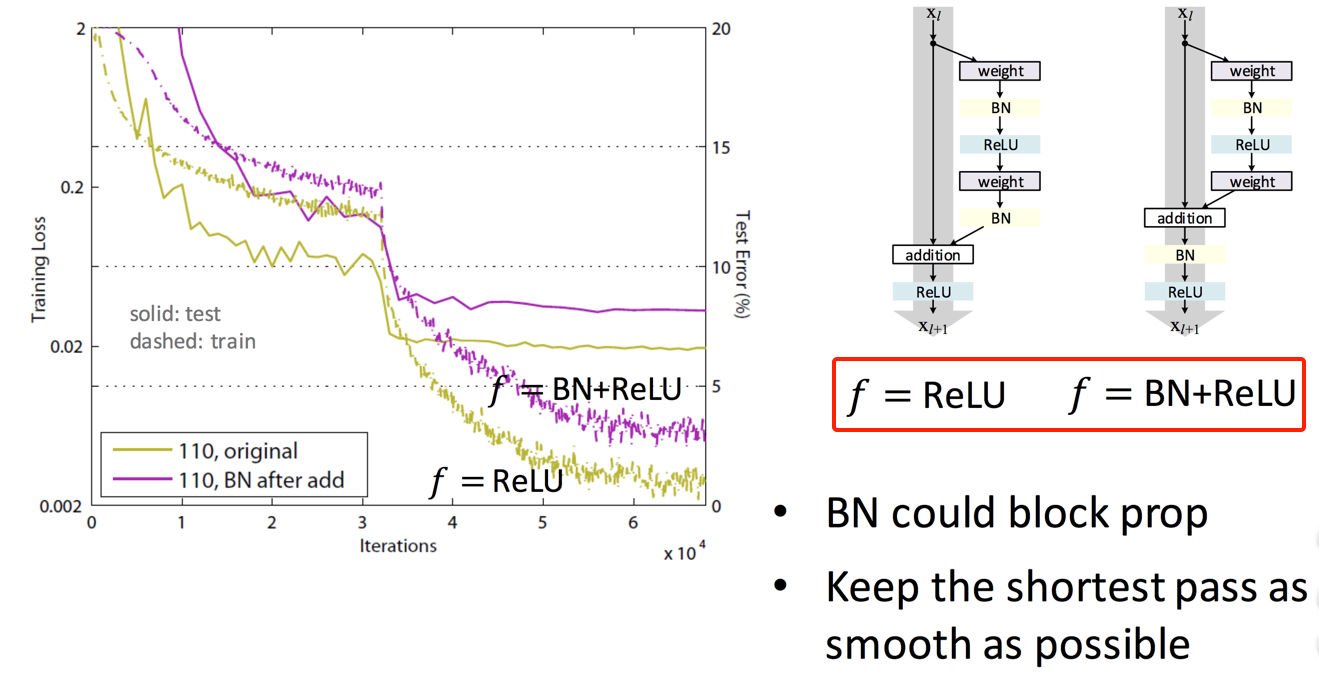
- 同时,作者也对比了shortcut mapping后前加BN的效果,发现BN可能会阻挡了网络的信息传播;总之,还是保持shortcut尽可能平滑,如下图:
- 这里作者对比了多种shorcut mapping的方式,发现如果用identity效果是最好的
- residual net: 18层,是和34层结构一样,只不过每个moodule中conv的个数不一样
- Bottleneck residual module
- bottleneck结构用于ResNet50/101/152以及更深的网络中,作者文中阐述引入bottleneck结构主要是从实际训练成本上考量(因为non-bottleneck实际确实会有一些精度的提升)
- bottleneck结构是: 降维的\(1 \times 1 \)的conv + ReLU + \(3 \times 3 \)的conv + ReLU + 增维的\(1 \times 1 \)的conv + elewise-add + ReLU
- 其中,降维的比例是4倍,升维的比例也是4倍(除了每个module的第一个bottleneck是降低2倍,第一个module的第一个bottleneck是没有降维)
- resnet50/101/152层也是和浅层网络一样,由4个modules组成,每增加一个module,特征维度降低一倍,kernel个数增加一倍(第一个module中kernel个数增为4倍),即每个module的第一个bottleneck的输出kernel个数是输入kernel个数的一倍,而该module内的其他bottleneck的输入和输出kernel个数一致
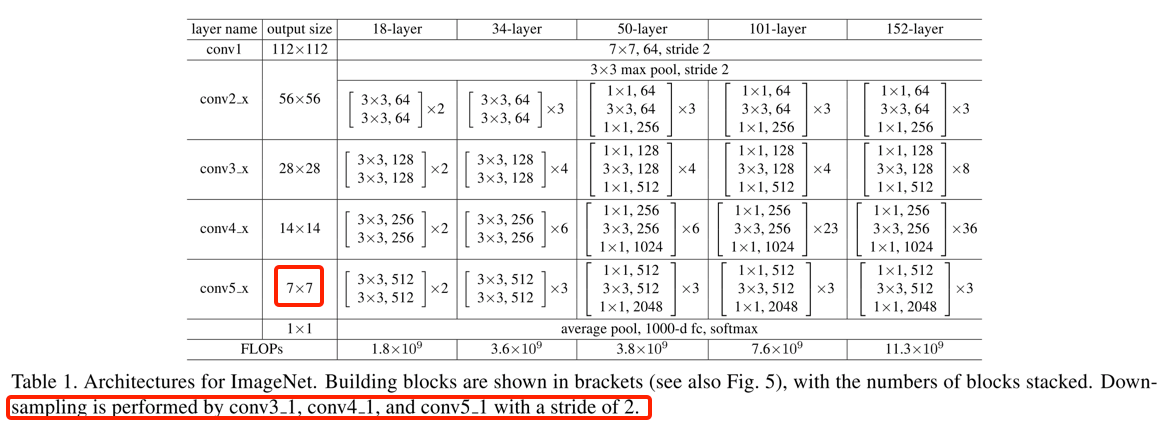
- 所有的resnet网络结构如下图:
写在后面
- 大佬的实验分析真的是很详尽,而对这些其中细节的实验对比(比如relu的位置,shortcut的类型等等)也能够作为设计网络的trick用于实际任务中