paper: Object-Contextual Representations for Semantic Segmentation
code: PyTorch
Abstract
- OCR是MSRA和中科院的一篇语义分割工作,结合每一类的类别语义信息给每个像素加权,再和原始的pixel特征concat组成最终每个像素的特征表示,个人理解其是一个类似coarse-to-fine的语义分割过程。
- 目前cityscape的分割任务中,排名最高的还是HRNetv2+OCR,参考paperswithcode
- OCR的整体方法流程图如下
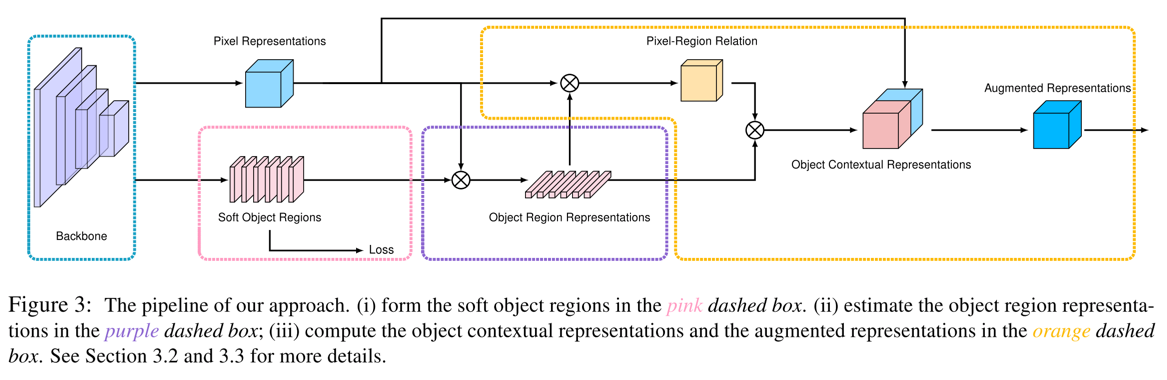
Details
- OCR的motivation是为了将每个pixel和其对应的类别信息结合起来,构造更加鲁棒的像素的特征表达。下图和ASPP的对比能够比较明显看出来。

- 每一个像素最终的特征表达方式如下面的公式及处理流程如下所示:
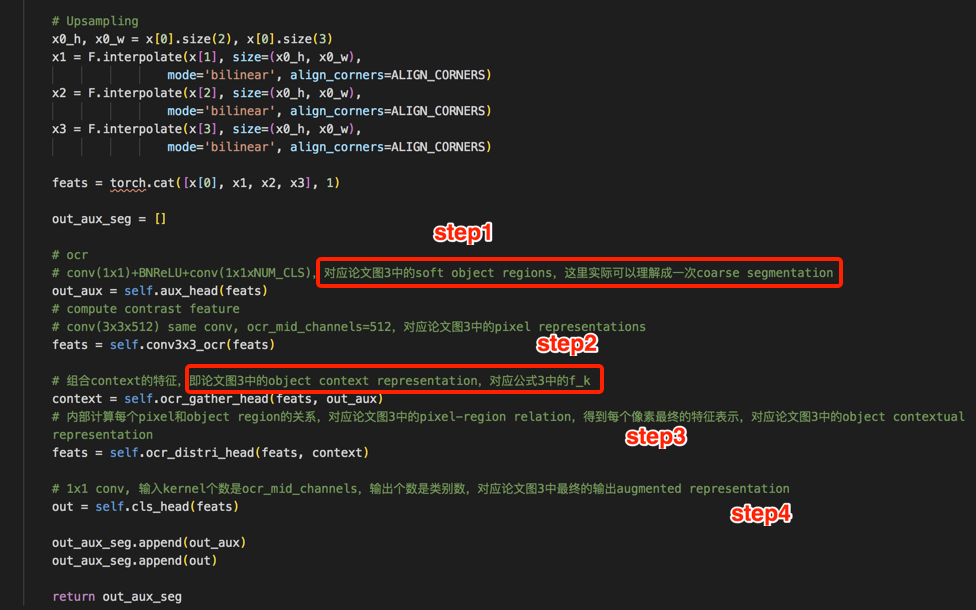
- step1: 计算一个coarse的segmentation结果,即文中说的soft object region
- 实现过程:从backbone(ResNet或HRNet)最后的输出的FM,再接上一组conv操作,然后计算cross-entropy loss
- step2: 结合图像中的所有像素计算每个object region representation,即公式中的\( f_k \)
- 实现过程:对上一步计算的soft object region求softmax,得到每个像素的类别信息,然后再和原始的pixel representation相乘
- step3: 利用object region representation和原始的pixel representation计算得到pixel-region relation,即得到公式中的\( w_ik \)
- 实现过程:将object region representation和pixel representation矩阵相乘,再求softmax
- step4: 计算最终每个像素的特征表示
- 实现过程:将step3的结果object region representation矩阵相乘,得到带有权重的每个像素的特征表示,并和原始的pixel representation连接到一起
- step1: 计算一个coarse的segmentation结果,即文中说的soft object region
- 代码
- 论文读完,晕晕乎乎的,没想明白按文中的表述怎么实现,看代码发现还是比较清晰的,文中提到的多种转换全部是通过不同size的conv实现的
- OCR的整体流程
- step2对应的代码
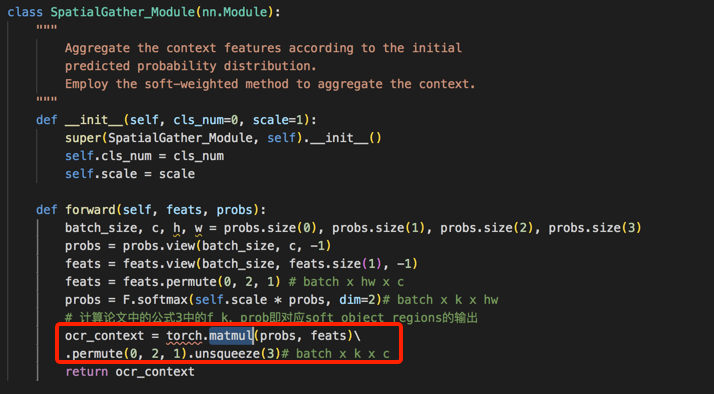
- step3对应的代码
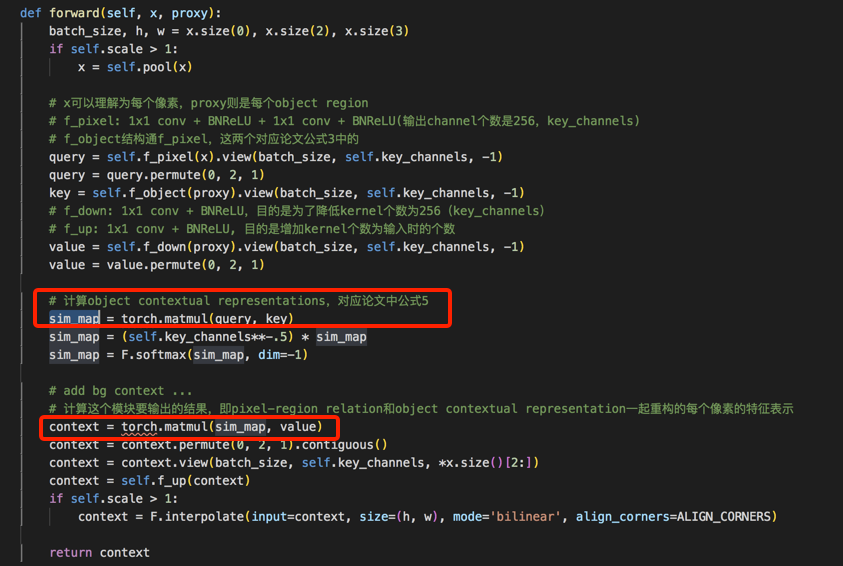
- 如下的OCR流程图,更为清晰的表示整体流程,以及和文中公式之间的对应关系(截图来自这里)
- 性能
- OCR和其他类似功能模块的速度对比
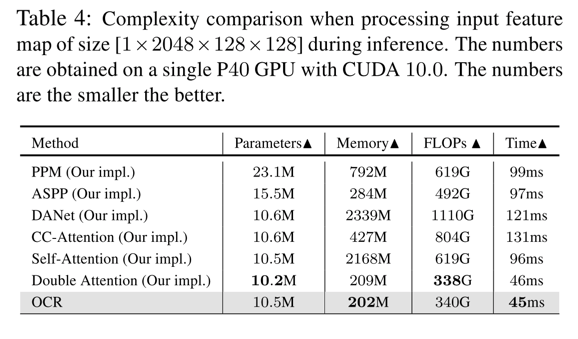
- mIoU对比见文中表格(太长了…)
- OCR和其他类似功能模块的速度对比
写在后面
- 本文也引入了一个auxiliary loss,PSPNet中也有引入。如果将网络分成多个stage,而后一个stage依赖与前一个stage的话,对前一个stage引入一个auxiliary loss来监督训练(loss设置一个权重,PSP中和本文都是0.4),对性能提升是有帮助的