paper: Feature Pyramid Networks for Object Detection
Abstract
- 作者的出发点很简单,就是为了将多尺度引入到网络中,同时引入多余的资源占用问题
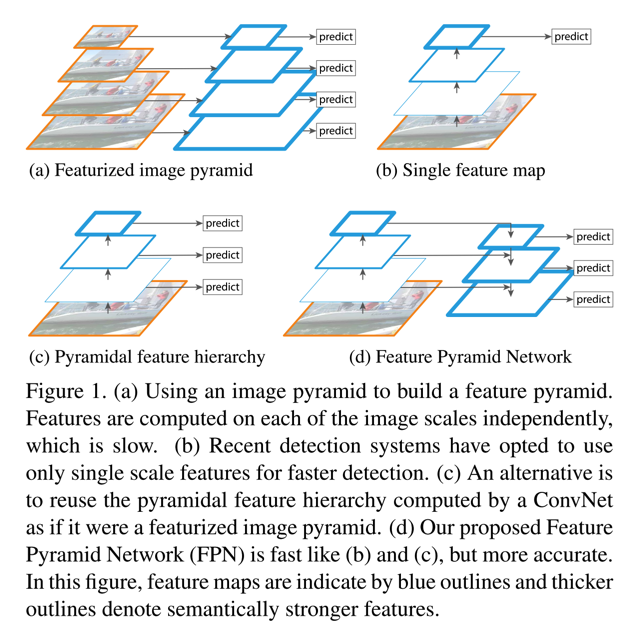
- 下图是对比多个不同的pyramidal hierarchy的结构
- 通过上图能看到,featurized image pyramid是对图像多尺度处理,训练时会很耗时,pramidal feature hierarchy(如ssd)则是选取不同的特征用以预测,但是如果选取的层比较靠后,会对小目标的检测有影响
- 下图是对比多个不同的pyramidal hierarchy的结构
- 对比现有的多种不同的多尺度的网络结构,FPN的关键不同在于:
- 将top-down的网络层和bottom-up的结构通过lateral connection连接起来,同时,每一个尺度下连接后的特征都会用来做预测
- 至于bottom-up,本身就是Conv的正常的前向过程
- top-down结构在ECCV16年的一篇文章中已提出(也是Facebook的,Learning to Refine Object Segments),不同之处在于,那篇文章是最终只是用的最后的finest的层,而不像FPN对每一层都有一个预测
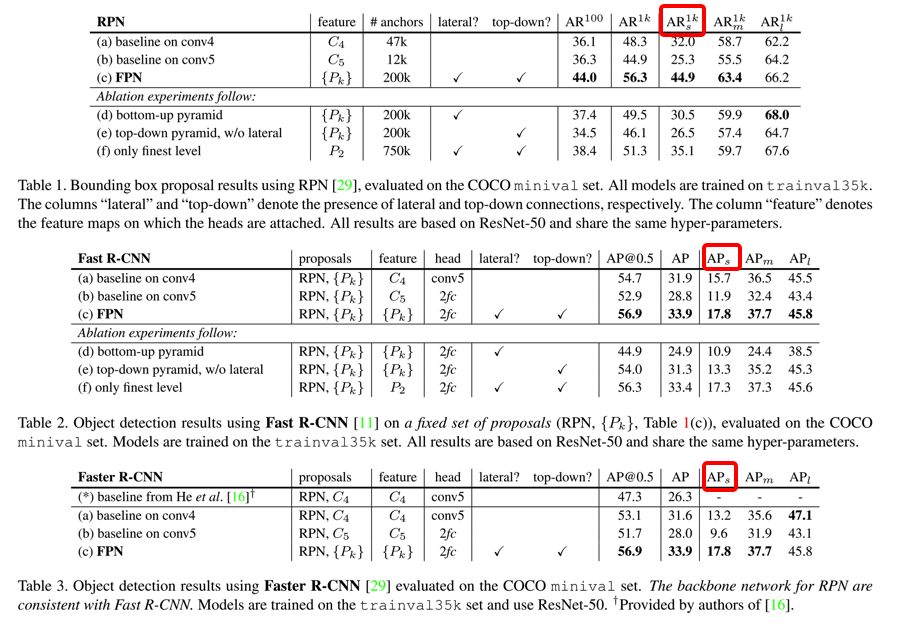
- FPN对小目标的效果明显提升了,参考下图
Details
- 如何保持多尺度以及如何将lateral connection如何进行?
- 首先参考图例:
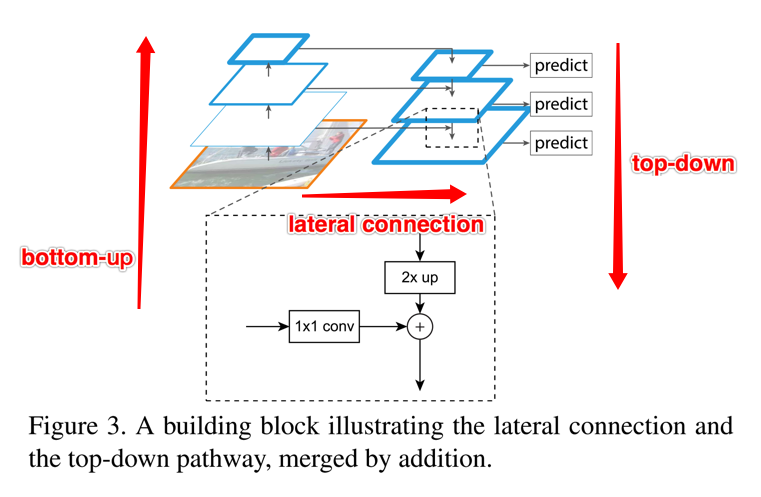
- lateral connection,相当于三个操作
- 对被选中的bottom-up的某一层执行1*1卷积,该操作可以实现对channel的更改
- 对与该层对应的top-down的上一层采用一个Upsampling(作者用最近邻的方式)将fm从上一层扩增2倍到当前层(主要为了和横向过来的层保持尺度的统一方便merge)
- 将刚才两个操作后的特征,通过element-wise的addition方式merge到一起
- 多尺度,作者对每一层都去获取一个prediction的结果,而在prediction之前,先对merged feature map执行一个3*3的卷积操作(作者给出的理由是通过这个操作来减少upsampling操作的混叠效应,可以理解使得最终的特征更鲁棒)
- 作者采用的所有pyramid level都是使用256个channel
- 首先参考图例:
- 如何和RPN结合?
- 作者用FPN替换RPN的输入特征层,即对上述的每一个merged feature map后添加一个跟着两个1*1卷积的3*3的conv(文中表述为network head)
- 同时,因为FPN本身已经实现来多尺度,所以在每一个merged feature map层设置anchor的scale统一,只保留不同的长宽比
- 因此,最终所有层anchors的area是\(32^2, 64^2, 128^2, 256^2, 512^2\),最后一项是下面说的P6
- 同时,多个level的head参数共享,作者实验表明共享与否对accuracy影响不大,原因应该就在于不同尺度的merged fm已经足够具有表达能力
- 实验用的是ResNet50作为backbone,将RPN的小网络用于ResNet的4个stage模块的最后一个residual单元,即{C2,C3,C4,C5},对于conv2、conv3、conv4、conv5, 相对原图的缩放倍数分别为{4,8,16,32},得到{P2, P3, P4, P5}
- RPN预测anchor时,使用的整体特征层数多了一个P6,即{P2, P3, P4, P5, P6},是在conv5的基础上再进行一次降采样的结果,在RoI pooling时没有使用盖层
- 如何与Fast RCNN结合?
- 这里的关键就是RoI pooling层了,即如何将不同的RoI分配给不同层的pyramid level
- 论文中给出了一个映射公式计算RoI对于的特征层\( P_k \),即\(P_k = ceil(k_0 + log2(\sqrt(wh) / 224))\),其中224是ImageNet上经典的网络输入图像大小,这个公式相对于保证了,对于scale越小的RoI,映射到越高分辨率的层上
- 网络结构上,由于ResNet的conv5已经用于构造feature pyramid了,因此,作者对构造的feature pyramid直接进行RoI pooling,并在后面接上两个1024维的FC层,然后再接上对应的classification分之和bbox regression分支
- 不足之处
- 按文中所述,在GPU上,FPN也就5fps,这个速度还是有点低的,应该主要还是在于two-stage的检测的通病吧